Archiv der Kategorie: XML/XSL
XML Prague 2013
Guten Morgen aus Prag, gerade beginnt die 8. Konferenz XML Prague, aufgrund des Erfolgs jetzt zum zweiten Mal in großen Hörsaal der wirtschaftswissenschaftlichen Fakultät. Als Single Track Conference ist es (für mich) äußerst entspannend, mich nicht zwischen verschiedenen, parallelen Vorträgen entscheiden zu müssen.
Der Tag beginnt mit der Vorstellung der Sponsoren: MarkLogic, ExistSolutions, Oxygen (Version 14.2. kommt nächste Woche).
Michael Kay: Multi-user interaction using client-side XSLT
Warum sollten wir am Server statisches XML bereitstellen und im Browser mittels XSLT 2.0 aufbereiten? Michael Kay zeigt ein technologisches cooles Beispiel der Saxon-Dokumentation. Aber all dies könnte auch von Server-side Code erledigt werden?
Warum sollten wir XSLT verwenden, wenn wir auch gleich JavaScript verwenden können?
Es gibt einen offensichtliche Vorteil immer dann, wenn die Quelldaten in XML vorliegen, aber auch dann stellt sich die Frage, inwieweit ich dem Browser XML statt XHTML anbieten möchte, inwieweit ich Teile meiner Lösung (letztlich die XSLT-Programmierung) quasi öffentlich machen möchte.
Abel Braaksma: Efficient XML processing with XSLT 3.0 and higher order functions
Wow, der kommende Standard! Und »Effizienz«, eines meiner Lieblingsworte. Und »closures«, über die ich schon gehört habe… Was bedeutet das alles in einer Welt, in der nur wenige (wenn überhaupt) XSLT-2.0-Funktionen angekommen sind?
„?“ als neuer Operator zur Inline-Definition neuer Funktionen – wer hätt gedacht, dass es so einfach sein kann, die Syntax bestehender Umgebungen mit einem Zeichen so mächtig zu erweitern?
Spannend: Abrasoft wird dieses Jahr einen distributed streaming XSLT 3.0 processor veröffentlichen. Es wird interessant sein, wie sich weitere Mitspieler im doch übersichtlichen Markt der XSLT-Prozessoren auswirken. Und was distributed in diesem Zusammenhang bedeutet.
George Bina: An XML Solution for Legal Documents
Wie verwaltet eine Software-Firma die notwendigen, unterschiedlichen End User License Agreements? Natürlich per XML. Neben einem recht einfachen Schema für die Dokumente gibt es natürlich die zwei Typen von Wiederverwendung:
- bedingte Ausgabe (Condition, Gültigkeiten) wird für einzelne Textteile verwendet: Über Publikationsprofile wird die Sichtbarkeit der Textabschnitte gesteuert.
- referenzieren (importieren) von vorhandenen Fragmenten: per XInclude können ganz bestimmte Elemente des Schema wiederverwendet werden
Die nötigen Ergänzungen für OxygenXML zur Bearbeitung gibt es bei GitHub.
Q: Warum wurde nicht einfach DITA verwendet? A: Es wäre sehr viel aufwändiger gewesen, DITA geeignete anzupassen als eine Lösung mit 10 Elementen zu erstellen.
Gerrit Imsieke: Conveying Layout Information with CSSa
Die Beiträge von Gerrit Imsieke in der XSL List sind immer lesenswert!
Ein Zwischenformat für die Vermittlung von n Eingabeformaten zu m Ausgabeformaten reduziert den Bedarf an Konvertern von n×m auf n+m. Dabei müssen aber bestimmte (z.B. Layout-) Informationen „gerettet“ werden. Um das in der XML-Umgebung umzusetzen, sind XML-Attribute geeignet. In dem Zwischenformat, dass le-tex verwendet, landen diese Informationen in Elemente und Attribute in einem eigenen Namespace css:.
Die Erzeugung von IDML (das XML-Format für InDesign-Dokumente) lobt er zu Recht. Alles in allem ein überzeugender Use-Case für den Einsatz der X-Technologien.
Romain Deltour: XProc at the heart of an ebook production framework
Ich dachte, es würde auch ein Projekt gezeigt, aber es war nur eine abstrakte Vorstellung der Bausteine des im Titel genannten Frameworks. Am Ende – und das ich nicht abwertend gemeint – war dieser Vortrag eine weitere Werbung für XProc zum Aufbau von XML-basierten Verarbeitungs-Prozesse.
Patrick Gundlach: Fully automatic database publishing with the speedata Publisher
Jetzt geht es um XSL-FO++, also nicht XSL-FO, sondern das Tool basiert auf LuaTEX.
Die Aufgabe maximize page usage ist komplex für automatisch erzeugte PDF-Dokumente und mit XSL-FO nur schwer oder gar nicht möglich. Für derartige und andere „dynamische“ Regeln muss der Layout-Prozessor mit dem Renderer „reden“. Im Produkt speedata Publisher wird das Input-XML auf Basis spezieller Layoutbefehle (in XML formuliert) verarbeitet. Dabei kommen interaktive Konzepte zum Einsatz, die adaptives Layout ermöglichen.
In der Frage-Session geht es scheinbar primär darum, dass die XSL-FO Working Group beim W3C mangels Interesse eingeschlafen sei…
DeltaXML Ltd: Representing Change Tracking in XML Markup
Änderungsmarkierung ist schon länger eine Herausforderung und es ist mehr als nur die Änderungsanzeige nach dem Vergleich zweier Dokumente. Auf jeden Fall gibt es derzeit keinen Standard, wie Änderungen in Dokumenten markiert werden. So ein Standard, d.h. unabhängig von einem bestimmten XML-Vokabular, böte ein Vielzahl von Möglichkeiten. http://www.w3.org/community/change/ ist die Webseite der »Change Tracking Markup Community Group«.
DeltaXML zeigt neue Konstrukte um einen Hierachiewechsel abzubilden. Wenn zum Beispiel ein Wort im Text fett dargestellt wird, ergab sich bislang immer folgende umständliche Abbildung:
In diesem Satz ist ein fettesfettes Wort.
Aber wie soll eine derartig hinterlegte Änderung dann angezeigt werden?
Alex Milowski: Local Knowledge for In Situ Services
Im Kern geht es um das „semantische Web“, in dem durch bestimmte Auszeichnungen die Inhalte beliebiger Webseiten besser auswertbar werden. Die hier empfohlene Technik dazu ist RDFa. Die Beispiele zeigen auch die Möglichkeit Bilder in einer regelbasierenden Form zu kommentieren.
Die Versuche der Organisatoren, den Vortragenden zu langsameren Sprechen zu motivieren, waren nicht besonders erfolgreich.
John Snelson: RDF for the XML Enthusiast
Und noch einmal RDF – jetzt ohne „a“. Ein Tweet:
Uche Ogbuji @uogbuji Aah! A dozen years after the self-inflicted wound of #RDF-#XML, I’m finally at a conference where everyone uses a saner syntax 🙂
Uche Ogbuji: Introducing MicroXML
Uche beginnt – nach einem „Happy Birthday“ für XML – mit einem Rückblick, welche Formate als Konkurrenten zu XML in Stellung gebracht wurden. Die MicroXML Community reduziert die Optionen der XML-Spezifikation auf ein Minimum, im Kern bleibt well-formed XML ohne Namespaces übrig. Und daran entzündet sich die Diskussion, denn z.B. xsl: scheint so unvermeidbar zu sein…
So, für wen ist µXML dann gedacht? »It’s for those who just don’t give a damn anymore!« Also für alle, die genug Probleme mit den Komplikationen von XML hatten…
Vorschläge zur Abbildung z.B. des xsl-Namespace sind xsl.template oder xsl-template
Maik Stührenberg: Quo vadis XML?
Nach dem Appell zur Reduktion vom XML mehr oder weniger auf die 1.0-Recommendation folgt nun ein Beitrag, der einen Blick in die Zukunft verspricht. Natürlich beginnt es mit einem Rückblick… der in eine Vorstellung akademischer Konzepte führt, die auf XML mit mehr oder weniger Kompatibilität basieren. Der Vergleich des 15-jährigen XML-Standards mit einem Teenager war noch unmittelbar einsichtig, die Besonderheiten von XStandoff, LMNL, FtanML etc. sind wohl Lösungen für ganz bestimmte Herausforderungen.
(Leider musste ich mich um aktive Projekte kümmern, so dass ich die weiteren Beiträge nicht zusammenfassen konnte.)
Veröffentlicht unter XML/XSL
Kommentare deaktiviert für XML Prague 2013
Wähle drei Töpfe
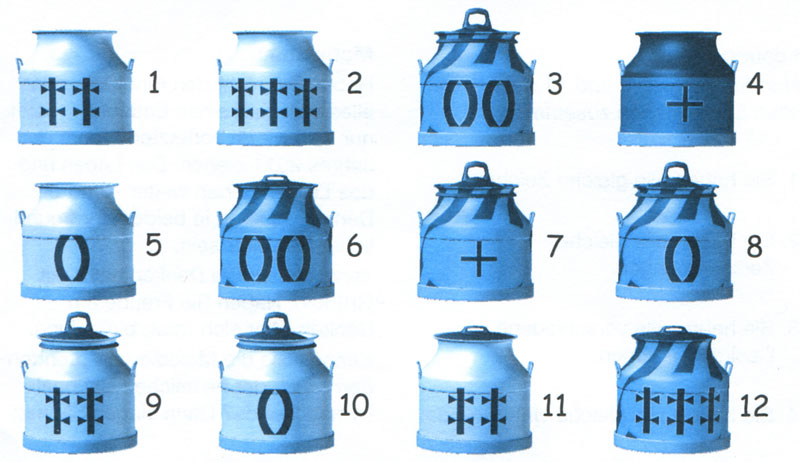
Jeder Topf hat vier Eigenschaften:
- verschiedene Deckel: kein Deckel, flacher Griff, hoher Griff
- verschiedene Farben: hell, gestreift, dunkel
- verschiedene Zeichen: Ring, Kreuz, Doppelkreuz
- verschiedene Zeichenanzahl: 1, 2 oder 3
Es sollen genau drei Töpfe so ausgewählt werden, dass für jede der vier Eigenschaften alle Töpfe entweder den gleichen Wert oder alle unterschiedliche Werte haben.
XML-Notation
Die Eigenschaften sind Attribute (zur Vereinfachung nenne ich diese a, b, c und d) und jedes Attribut muss einen von drei möglichen Werten annehmen (1, 2, 3).
<pots>
<pot a="1" b="1" c="3" d="2"></pot>
<pot a="1" b="1" c="3" d="3"></pot>
<pot a="3" b="2" c="1" d="2"></pot>
<pot a="1" b="3" c="2" d="1"></pot>
<pot a="1" b="1" c="1" d="1"></pot>
<pot a="2" b="2" c="1" d="2"></pot>
<pot a="3" b="2" c="2" d="1"></pot>
<pot a="3" b="2" c="1" d="1"></pot>
<pot a="3" b="1" c="3" d="2"></pot>
<pot a="3" b="1" c="1" d="1"></pot>
<pot a="2" b="1" c="3" d="2"></pot>
<pot a="3" b="2" c="3" d="3"></pot>
</pots>Lässt sich die Lösung mit einem XPath-Ausdruck angeben? Nein, wohl nicht, und ich bin auch nur auf eine brute force-Lösung gekommen, die mir wenig elegant erscheint:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:transform xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="2.0"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:my="my"
exclude-result-prefixes="#all">
<xsl:output indent="yes" />
<xsl:template match="pots">
<xsl:variable name="a" as="node()*" select="my:triples(*, 'a')" />
<xsl:variable name="b" as="node()*" select="my:triples(*, 'b')" />
<xsl:variable name="c" as="node()*" select="my:triples(*, 'c')" />
<xsl:variable name="d" as="node()*" select="my:triples(*, 'd')" />
<result>
<!-- only triples which are present for all attributes are returned -->
<xsl:for-each select="$a[. = $b][. = $c][. = $d]">
<xsl:sequence select="." />
</xsl:for-each>
</result>
</xsl:template>
<!-- this function returns all valid triples for a single attribute -->
<xsl:function name="my:triples" as="node()*">
<xsl:param name="nodes" as="node()+" />
<xsl:param name="attr" as="xs:string" />
<!-- look for common values -->
<xsl:for-each select="$nodes">
<xsl:variable name="t1" select="." />
<xsl:for-each select="$t1/following-sibling::*[@*[name() eq $attr] eq $t1/@*[name() eq $attr]]">
<xsl:variable name="t2" select="." />
<xsl:for-each select="$t2/following-sibling::*[@*[name() eq $attr] eq $t1/@*[name() eq $attr]]">
<triple>
<xsl:value-of select="(my:pos($nodes, $t1), my:pos($nodes, $t2), my:pos($nodes, .))" />
</triple>
</xsl:for-each>
</xsl:for-each>
</xsl:for-each>
<!-- look for distinct values -->
<xsl:for-each select="$nodes">
<xsl:variable name="t1" select="." />
<xsl:for-each select="$t1/following-sibling::*[@*[name() eq $attr] ne $t1/@*[name() eq $attr]]">
<xsl:variable name="t2" select="." />
<xsl:for-each select="
$t2/following-sibling::*[@*[name() eq $attr] ne $t1/@*[name() eq $attr]
and
@*[name() eq $attr] ne $t2/@*[name() eq $attr]]">
<triple>
<xsl:value-of select="(my:pos($nodes, $t1), my:pos($nodes, $t2), my:pos($nodes, .))" />
</triple>
</xsl:for-each>
</xsl:for-each>
</xsl:for-each>
</xsl:function>
<xsl:function name="my:pos" as="xs:string">
<xsl:param name="nodes" as="node()+" />
<xsl:param name="node" as="node()" />
<xsl:value-of select="count($nodes[$node >> .]) + 1" />
</xsl:function>
</xsl:transform>Wer kann eine elegantere Lösung anbieten?
Veröffentlicht unter XML/XSL
Kommentare deaktiviert für Wähle drei Töpfe
Textänderungen anzeigen
Ich habe das Tool XTC = XML Tree Compare von Martin Achtziger http://www.xmldifftool.com/ schon auf der tekom-Tagung vorgestellt und in meinem Blog erwähnt. Im praktischen Einsatz in Projekten geht es mittlerweile nicht um so banale Dinge wie die Performance (die mit der aktuellen Version 3.x gefühlt doppelt so schnell ist) sondern um die Feinheiten, die letzten Details.
Ein automatisch erstellter Vergleich ist immer um ein Vielfaches wirtschaftlicher als jedes vorstellbare manuelle Verfahren. Mit der einmaligen Anker-Technik verfügt das Tool über eine Funktion, die es ermöglicht, dass Blöcke anhand eindeutiger Kennungen einander sauber zugeordnet werden, und nicht ein neu eingeschobener Abschnitt 1.3 verzweifelt mit dem alten 1.3 verglichen wird, der ja jetzt die 1.4 ist. Auf diese Weise können auch größere Umstellungen erkannt werden und die Änderungsanzeige hält sich nicht mit Irrelevantem auf.
Bleibt die Anzeige gelöschtem, geändertem und neuem Text. Hier ist der Automat im Nachteil, weil er nicht weiß, wie wir tatsächlich geändert haben, was die Absicht war. Er kann nur den alten und neuen Satz (eigentlich: Textknoten) betrachten und technisch analysieren. Zum Einsatz kommt hier zunächst ein bekannter Algorithmus: Longest common substring.
Beispiele
V1: Der Absatz enthält ganz und gar nichts.
V2: Der Absatz enthält gar nichts.
Diff: Der Absatz enthält ganz und gar nichts.
Der längste gemeinsame Text ist der Textanfang bis einschließlich »ga«. Ideal wäre natürlich dies gewesen: Der Absatz enthält ganz und gar nichts. Aber dies ist für den Computer wohl kaum zu erkennen.
V1: Datentyp des Feldes, sofern Ausprägungen vorgebbar.
V2: Datentyp des Feldes, genau dann wenn Ausprägungen vorgebbar.
Diff: Datentyp des Feldes, sofer
genau dann wenn Ausprägungen vorgebbar.
Natürlich erschwert es auch hier die Lesbarkeit, dass vom Ende sowohl »sofern« als auch »wenn« mit einem »n« enden. Ideal wäre hier ein die Ausdehnung auf ganze Wörter: Datentyp des Feldes, sofern
genau dann wenn Ausprägungen vorgebbar.
Aber die Ausdehnung auf ganze Wörter kann auch unerwünscht sein, wenn zum Beispiel nur Anfangs- oder Endbuchstaben ergänzt oder Tippfehler korrigiert wurden:
V1: Die Erklärung war nicht hinrecihend.
V2: Die Erklärungen waren nicht hinreichend.
Diff: Die Erklärungen waren nicht hinreci
ichend.
Hier wäre die Ganzwortmethode wohl eher hinderlich: Die Erklärung
Erklärungen war
waren nicht hinrecihend
hinreichend.
Fragen
In meinen Augen stellen sich zwei Fragen:
- Sollten Optimierungen beim Textvergleich vom Diff-Tool oder von einer nachgelagerten Aufbereitung durchgeführt werden?
- Wie soll diese Optimierung aussehen?
Gerade-ungerade Sudoku

Auch als Sudokulino ist mir diese Form eines Sudoku begegnet. Naben den üblichen Bedingungen – jede Ziffer nur einmal pro Reihe und Spalte – gilt hier noch: Rechts, links, oben, unten benachbarte Zahlen dürfen keine Nachbarzahlen sein, sie müssen sich um mehr als 1 unterscheiden.
XML-Struktur
In Erinnerung an Michael Kays XSLT-Lösung des Rösselsprungs (»Knight’s Tour«) fassen wir das XML ganz einfach, indem wir alle Felder einfach der Reihe nach angeben.
<fields max="6">
<field val="5"/><field /><field /><field /><field /><field val="2" />
<field /><field /><field /><field /><field val="4" /><field val="6" />
<field /><field val="5" /><field val="3" /><field /><field /><field />
<field val="4"/><field /><field /><field /><field val="5" /><field />
<field val="2"/><field val="6" /><field /><field /><field /><field />
<field /><field /><field /><field /><field val="1" /><field val="3" />
</fields>Jetzt benötigt es Methoden, um für ein beliebiges Feld festzustellen, welche Ziffern gültig sind. Damit lassen sich alle eindeutigen Zuordnungen durchführen und nach ein paar Runden ist das Quiz gelöst. Was aber, wenn es einmal keine eindeutige Lösung gibt?
Veröffentlicht unter XML/XSL
Kommentare deaktiviert für Gerade-ungerade Sudoku
Markupforum Stuttgart 2011

Wenn Sie sich für das Programm dieser Veranstaltung zum Thema XML interessieren, finden Sie alle Infos auf http://www.markupforum.de/.
Diese neue Veranstaltung hat meiner Meinung gutes Fortsetzungs-Potential. Sicher werden – aufgrund der Ausrichtung der veranstaltenden Hochschule der Medien – auch zukünftig die technischen Voraussetzungen und Rahmenbedingungen für mögliche neue Geschäftsmodelle von Verlagen einen gewissen Vorrang haben, aber selbst beim Austausch von Video-Schnittdaten zwischen Applikationen kommt XML zum Einsatz! In gewisser Weise stehen die Verlage heute dort, wo sich die Technische Redaktion in der Industrie schon vor einiger Zeit war: Unter dem Druck, immer mehr Publikationen in mehreren Varianten und/oder Medien möglichst günstig zu publizieren. Insofern muss auf Seite der Verlage nicht alles neu erfunden werden…
Im folgenden einige Anmerkungen zu einigen Beiträgen, Vortragsfolien wird es auf der o.g. Webseite geben. [Ich musste lernen, dass es nicht einfach ist, zuzuhören und gleichzeitig schriftlich zu kommentieren.]
The Future of XSLT
Dr. Michael Kay spricht gerne über die Zukunft, da ihn keiner schelten kann, wenn er daneben liegt. Nach einem Rückblick auf die Wurzeln von XSLT folgt ein Blick auf die Gegenwart, die Stärken und Schwächen.
Either people love it, or people hate it
If your brain adjusts to the XSLT wavelength…
Nachdem es mit XSLT im Web-Browser seit 2001 nicht weiter gegangen ist, hat sich die Weiterentwicklung auf die Server-seitige Nutzung konzentriert. Dort gibt es unterschiedliche Geschäftsmodelle:
- Do it for fun
- Give it away and hope to make money on something else (Altova)
- Bundle it as part of something expensive (IBM, Intel, MarkLogic)
- Do it cheaply, sell it cheaply (Saxonica)
Die Weiterentwicklung zu XSLT 3.0 liefert im Wesentlichen Verbesserungen für die Top-End-Anwender. Aber welche Möglichkeiten existieren für die Verwendung im Web-Browser? Eine Möglichkeit wäre JavaScript als Virtuelle Maschine (VM) für andere Sprachen zu verwenden. Und daran arbeitet Michael Kay derzeit.
HTML5
Sehr unterhaltsam… ein Beitrag, mit dem uns Michael Jendryschik ermuntern will, es mit HTML5 zu probieren.
Der DITA-Hype
Bildschirmpräsentation meines Beitrags
Warum Verlage XML sprechen sollten
Stell dir vor, es geht und keiner bekommt’s hin (Wolfgang Neuss)
Wie kommen wir an die Metadaten, die die „semantische Lücke“ zwischen Inhalten und der Suche danach schließen?
Metadaten sollen verständnisrelevante Informationen transportieren: Identifikation, Entdeckung, Auswertung, Management.
Eine willkommene Brandrede von Helmut von Berg für die semantische Auszeichnung von Inhalten. Was nicht gefunden wird, wird auch nicht gekauft!
Macht XML selig?
Wenn in der technischen Dokumentation das XML-strukturierte Vorgehen manchmal schlicht einen Notwendigkeit ist, so lassen sich im Verlagsbereich noch neue Geschäftsmodelle entwickeln. Spannend!
Looking behind ePub
Ein E-Book ist das, was ein Leser bereit ist auf einem elektronischen Medium zu lesen.
Der Standard ePUB 2.0 besteht aus den drei Sub-Standards OCF + OPF + OPS.
Durch den »Reflow« der Inhalte muss für bestimmte Layouts eine neue Lösung gefunden werden.
Dr. Victor Wang gibt einen Überblick über den Stand und die aktuellen Bemühungen zur Weiterentwicklung zu ePUB 3.0.
XML-Dokumente mit Schematron besser prüfen
Statt einer reinen Strukturprüfung wie bei DTD oder XML Schema wird hier regelbasiert geprüft, und ermöglicht so viel mächtigere Tests (Roger Costello, http://www.xfront.com/):
- Co-constraints
- Cardinality checking
- Algorithmic checking
Ich persönlich finde die hier sehr anschaulich von Prof. Hedler vorgestellte Prüftechnik äußerst interessant. Wenn wir ähnliches in bescheidenem Umfang mit kontextabhängigen Formatierregeln in FrameMaker umsetzen, wäre eine weiter gehende Unterstützung doch noch nützlicher.
InDesign und XML – wie geht es weiter?
Ein Überblick von Gregor Fellenz über die diversen XML-Features und Probleme von InDesign: Whitespace-Problem, IDML, ICML, XHTML-Export (z.B. für die ePUB-Erstellung).
InDesign als Datenzentrale? Eher nicht, insbesondere da Adobe die XML-Features seit InDesign CS4 nicht weiterentwickelt hat.
Also: InDesign als Rendering Engine, klassische DTP-Anwendung.
Proof of Concept: Wordpress via XSLT nach ICML, in InDesign verknüpft.
Der Stand der XML-Dinge

Anfang 2009 führte Scriptorium Publishing eine Umfrage unter dem Titel »The State of Structure« zu den Erwartungen an und Erfahrungen mit XML-strukturierten Autorenumgebungen und Prozessen durch. Über deren Ergebnisse habe ich im Mai 2009 kurz berichtet. Nicht zu schweigen davon, dass ich einige Erkenntnisse auch in einigen Vorträgen und Präsentationen berücksichtigen konnte.
Jetzt, Anfang 2011, zwei Jahre später ist es Zeit für ein Update dieser Umfrage, und Sarah O’Keefe, die größtenteils in Deutschland aufgewachsene Gründerin von Scriptorium Publishing, würde sich freuen, wenn diese Neuauflage eine stärkere internationale Beteiligung erfahren würde.
The State of Structure, 2011
Wenn Sie bereits XML-strukturiert arbeiten oder dies bei Ihnen geplant ist, nehmen Sie sich bitte ca. 15 Minuten Zeit und bis Ende Februar an der Studie teil. Als Teilnehmer bekommen Sie die Ergebnisse kostenlos; es werden auch zwei Amazon-Geschenkgutscheine verlost…
Veröffentlicht unter XML/XSL
Kommentare deaktiviert für Der Stand der XML-Dinge
MarkupForum: Publishing mit XML
Viele Konferenzen zu Themen rund um XML finden in den USA statt, die uns nächstgelegene Veranstaltung war bislang die Konferenz XML Prague, die ich 2010 zum ersten Mal besucht und über die ich in mehreren Beiträgen berichtet habe:
Nicht zuletzt von dieser Veranstaltung, sondern auch von einem gewissen Mangel an Veranstaltungen hierzulande, ließen sich die Organisatoren aus dem Umfeld der Hochschule der Medien in Stuttgart inspirieren, eine deutschsprachige Konferenz zu diesem Thema zu initiieren:
Unter dem Titel MarkupForum geht es zunächst an einem Tag, dem (leicht zu merkenden) 1.3.2011 in Stuttgart um Publishing mit XML.
Aktuell können Sie sich unter http://www.markupforum.de/ über das Programm informieren.
PS: Ich hätte nie im Leben angenommen, einmal mit Dr. Michael Kay auf einer Referenten-Liste zu stehen 🙂
Database Publishing mit FrameMaker
Ein nicht nur von der Seitenzahl her umfangreiches Projekt habe ich kürzlich abgeschlossen und wenn Sie die DMS Expo (26.-28.10.2010) besuchen, können Sie am Stand des VOI e.V. einen Blick auf das 956 Seiten starke Resultat werfen:

Die vom VOI in Zusammenarbeit mit der Beratungsgesellschaft Zöller & Partner herausgegebene »Marktübersicht Dokumenten-Management-Systeme« umfasst 956 Seiten und ist das Ergebnis einer effizienten Nutzung aktueller Technologien:
- Web-Frontend mit Datenbank zur Erhebung der Daten
- XML-Export aller Fragen und Antworten
- XSL-Preprocessing zur publikationsgerechten Aufbereitung mit
- Adobe FrameMaker
Dass Vorwort und Titel dabei herkömmlich formatbasiert umgesetzt sind, stört den Prozess ganz und gar nicht, bietet doch diese hybride Vorgehensweise den schnellsten Weg zu einer effizienten Lösung.
Weitere Details finden Sie in meinem Projektbericht »Database Publishing für Marktübersichten«.
Veröffentlicht unter FrameMaker, XML/XSL
Kommentare deaktiviert für Database Publishing mit FrameMaker
SVG wiederbelebt?
Nach der Übernahme von Macromedia und damit dem Flash-Format wurde es schlagartig still um SVG, ein auch von Adobe ursprünglich voran getriebener XML-basierter Standard für Vektorgrafiken. Adobe Illustrator gehörte zu den ersten Programmen mit SVG-Unterstützung, mit dem SVG Viewer brachte Adobe eine Browser-Plug-in auf den Markt.
![]()
Jetzt erschien als zunächst experimentelles Update für Adobe Illustrator CS5 in den Adobe Labs eine Erweiterung namens Adobe Illustrator CS5 HTML5 Pack, welches erweiterte Features beim Speichern von Grafiken als SVG anbietet.
Aber woher kommt das Interesse? Es zeigt sich, dass Flash eben doch nicht überall vorausgesetzt werden kann und zum noch in Entwicklung befindlichen Web-Standard HTML5 gehört neben CSS3 eben auch die Unterstützung für SVG-Grafiken. Da sich Adobe primär als Werkzeug-Lieferant für die Inhaltsschöpfer sieht, will man natürlich überall dabei sein, in der Flash-Welt wie in Umgebungen, in denen Grafiken und Animationen ausschließlich mit HTML, CSS und JavaScript erstellt werden.
Zur Erinnerung: Im April 2010 sorgte Steve Jobs für Aufsehen mit seinen »Thoughts on Flash«, die von Adobe gekontert wurden mit »Freedom of Choice«.
Wenn jetzt in SVG nur noch eine vernünftige Unterstützung für Textblöcke dazu käme…
PS: Die HTML5-Beispiele auf http://www.apple.com/html5/ sind schon recht beeindruckend (Achtung: Mit Internet Explorer wird’s nix…)
Veröffentlicht unter XML/XSL
4 Kommentare